

W poprzednim poście pokazałem jak uzyskać dostęp do usług Google Cloud. Ten post pokaże, w jaki sposób stworzyć pierwszy projekt i użyć Google Cloud Storage.
Wszystkie dane, które umieszczamy w cloud storage, znajdują się w bucketach. Można o nich myśleć, jak o takich katalogach nadrzędnych. Każdy bucket musi posiadać unikalną nazwę w obrębie całego clouda (nie mogą istnieć 2 buckety o tej samej nazwie w obrębie całej usługi, różni użytkownicy nie mogą mieć bucketów o tej samej nazwie). W ramach bucketu możemy tworzyć pliki i foldery podobnie jak na dysku twardym.
Obsługa przez konsolę
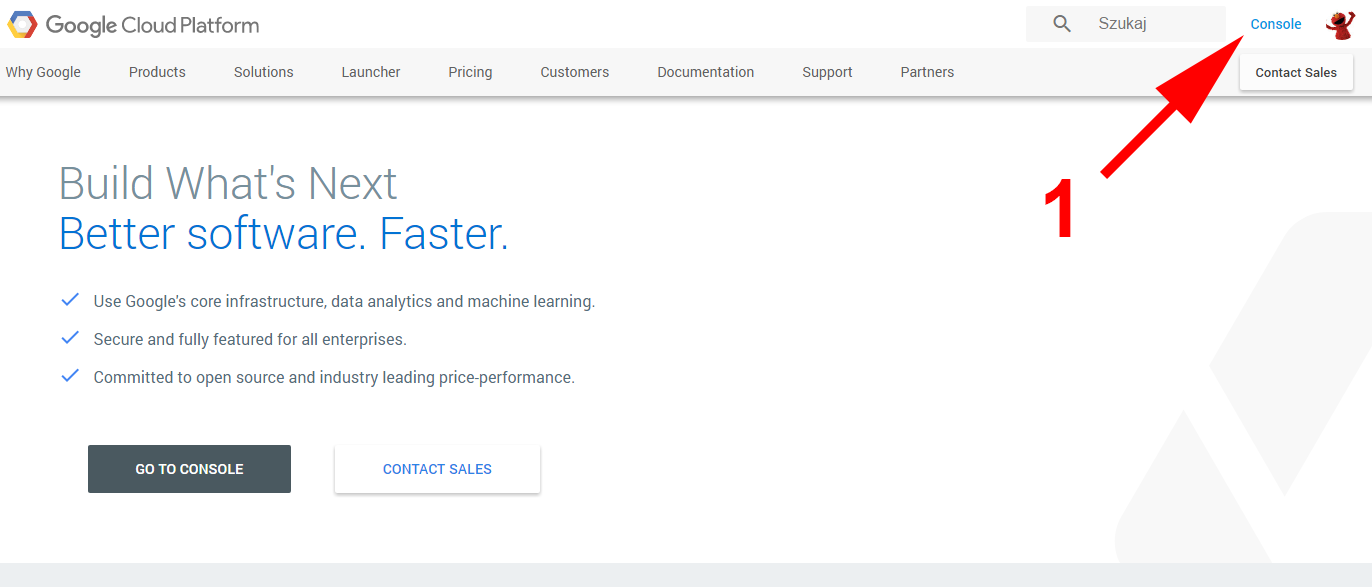
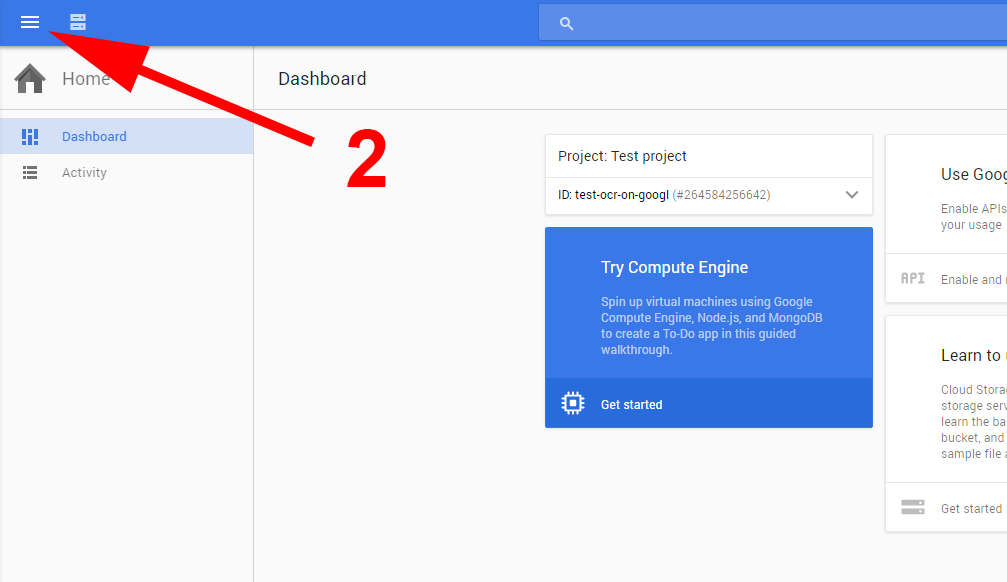
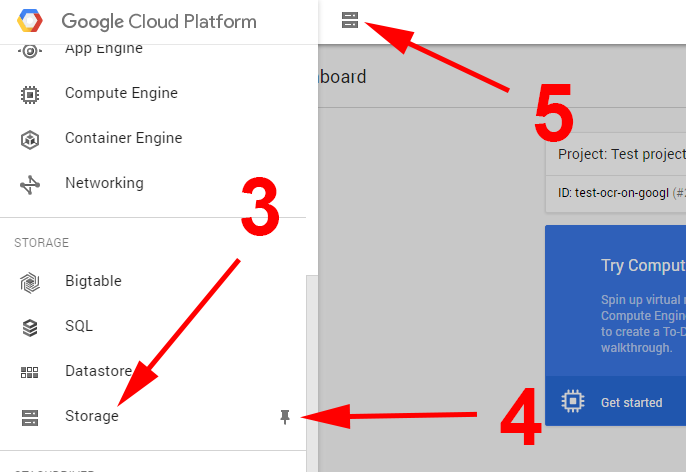
Zacznijmy od stworzenia bucketu przez konsolę administracyjną. Aby tego dokonać, należy wejść na http://cloud.google.com i kliknąć console [1] w prawym górnym rogu. Po wejściu na dashboard wchodzimy w menu [2] i wyszukujemy pozycję Storage [3]. Po najechaniu na opcję w menu pojawi się pineska [4], jeśli ją klikniemy, ikonka Storage pojawi się na pasku skrótów [5] i będzie ona widoczna zawsze bez wchodzenia w menu.
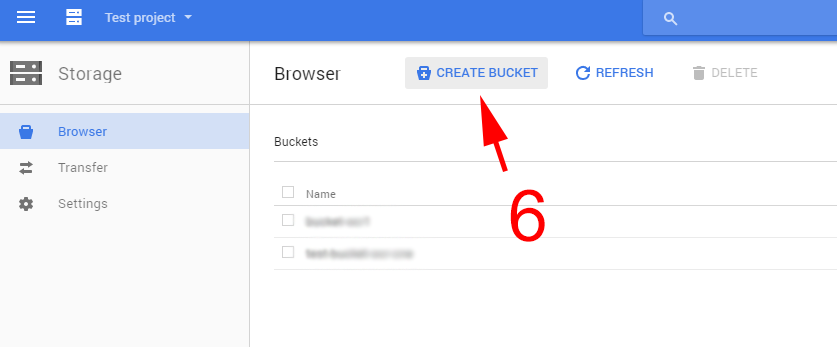
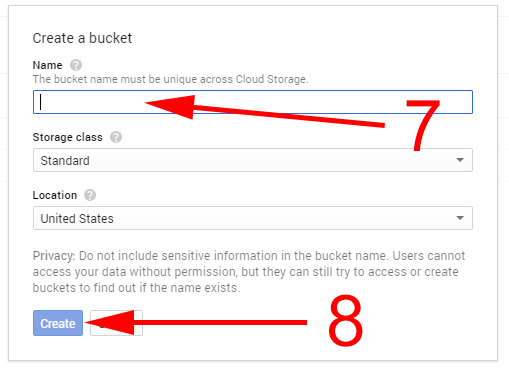
Następnie klikamy create bucket [6]. W okienku, które się pojawiło, nadajemy mu nazwę [7]. Reszta opcji pozostaje bez zmian. Nazwa może składać się z małych liter, podkreślenia (_) i pauzy (-). Jeśli jest to nazwa domeny (w takim wypadku trzeba udowodnić, że to nasza domena), musi rozpoczynać się i kończyć literą lub liczbą i może zawierać kropkę (.). Klikamy create[8] i otrzymujemy nowy, pusty bucket.
Na ekranie powinniśmy mieć widok pustego bucketu, z opcjami przesłania plików (upload files), folderów (upload folder) i tworzenia folderów (create folder).
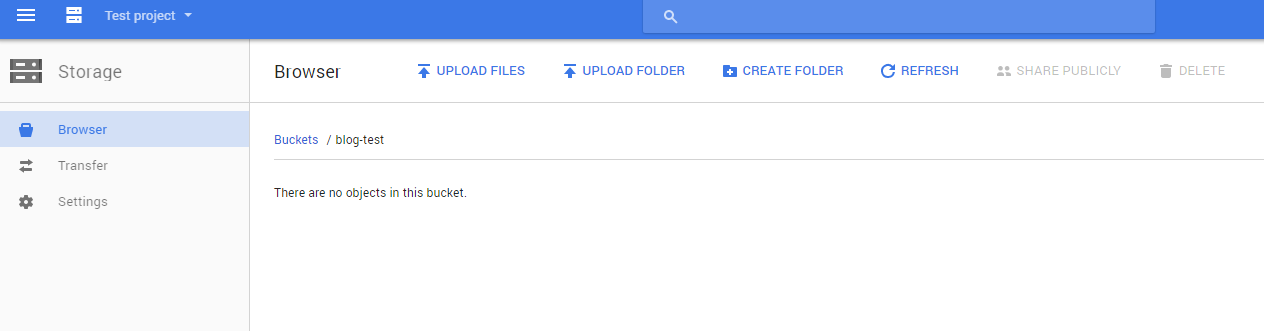
Spróbujmy wrzucić coś do bucketu. Klikamy na upload files i wybieramy jakiś obrazek. Następnie tworzymy folder, przechodzimy do niego i wrzucamy kolejny obrazek. Jeśli nie masz pomysłu, jaki obrazek wrzucić, możesz użyć kota z serem na głowie:

Programowa interakcja z Google Cloud Storage
Jak zawsze, gotowe kody można znaleźć na moim GitHubie pod adresem: https://github.com/mloza/google-cloud-storage
Usługa Cloud Storage byłaby bezużyteczna jeśli nie dałoby się nią sterować z poziomu kodu. Google przygotowało odpowiednie biblioteki, aby nam to umożliwić. Zacznijmy od stworzenia nowego projektu z wykorzystaniem Mavena i dodaniu zależności do pom.xml. Gotowy plik pom powinien wyglądać następująco:
| <?xml version="1.0" encoding="UTF-8"?> | |
| <project xmlns="http://maven.apache.org/POM/4.0.0" | |
| xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" | |
| xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> | |
| <modelVersion>4.0.0</modelVersion> | |
| <groupId>pl.mloza</groupId> | |
| <artifactId>google-cloud-storage</artifactId> | |
| <version>1.0-SNAPSHOT</version> | |
| <dependencies> | |
| <dependency> | |
| <groupId>com.google.apis</groupId> | |
| <artifactId>google-api-services-storage</artifactId> | |
| <version>v1-rev72-1.22.0</version> | |
| </dependency> | |
| </dependencies> | |
| <build> | |
| <plugins> | |
| <plugin> | |
| <groupId>org.apache.maven.plugins</groupId> | |
| <artifactId>maven-compiler-plugin</artifactId> | |
| <configuration> | |
| <source>1.8</source> | |
| <target>1.8</target> | |
| </configuration> | |
| </plugin> | |
| </plugins> | |
| </build> | |
| </project> |
W poprzednim poście (tutaj) pokazywałem jak wygenerować plik z kluczami dostępowymi. Będzie on nam teraz potrzebny. Należy go umieścić w katalogu resources. W moim przypadku nazywa się on client-secrets.json.
Listowanie bucketów
Zacznijmy od pierwszej operacji, jaką jest wylistowanie bucketów w ramach projektu.
Na początek musimy stworzyć obiekt storage za pomocą buildera. Potrzebuje on do działania HttpTransport, Credential i JsonFactory. HttpTransport tworzy się bardzo prosto, natomiast credentiale trzeba utworzyć przy pomocy wspomnianego wcześniej pliku client-secrets.json. Cały kod wygląda następująco:
| public class Main { | |
| public static void main(String[] args) { | |
| try { | |
| HttpTransport httpTransport = GoogleNetHttpTransport.newTrustedTransport(); | |
| JsonFactory jsonFactory = new JacksonFactory(); | |
| Credential credential = GoogleCredential | |
| .fromStream( | |
| Main.class.getClassLoader() | |
| .getResourceAsStream("client-secrets.json")) // 1 | |
| .createScoped(Collections.singleton(StorageScopes.CLOUD_PLATFORM)); // 2 | |
| Storage storage = new Storage.Builder(httpTransport, jsonFactory, credential) | |
| .setApplicationName("Test project") // 3 | |
| .build(); | |
| storage.buckets() | |
| .list("blog-test") | |
| .execute() | |
| .getItems() | |
| .forEach(i -> System.out.println(i.getName())); // 4 | |
| } catch (GeneralSecurityException | IOException e) { | |
| e.printStackTrace(); | |
| } | |
| } | |
| } |
Należy wskazać mu plik z kluczami do usługi [1], następnie określić jakie uprawnienia potrzebuje [2]. Gdy to już mamy możemy zbudować obiekt Storage do interakcji z Cloud Storage. Jako application name możemy podać cokolwiek [3] i powinno zadziałać. W kolejnym kroku wykonujemy listowanie [4], jako argument operacja przyjmuje project id (nie mylić z Project Name), w ramach którego utworzony został bucket. Jeśli wszystko zostało poprawnie ustawione, w konsoli powinniśmy zobaczyć nazwę utworzonego bucketu.
Zanim przejdziemy dalej, posprzątajmy troszkę kod, aby ułatwić tworzenie kolejnych operacji.
W pakiecie util tworzę sobie klasę CredentialsProvider o następującej zawartości:
| public class CredentialsProvider { | |
| public static Credential authorize() { | |
| try { | |
| return GoogleCredential.fromStream(CredentialsProvider.class.getClassLoader() | |
| .getResourceAsStream("client-secrets.json")) | |
| .createScoped(Collections.singleton(StorageScopes.CLOUD_PLATFORM)); | |
| } catch (IOException e) { | |
| Throwables.propagate(e); | |
| } | |
| return null; | |
| } | |
| } |
Zapewni ona stworzenie credentiali. Następnie kod przenoszę do testu jednostkowego tak, aby kolejne operacje można było dodawać jako kolejne testy. Po posprzątaniu kod przybiera postać:
| public class GoogleCloudStorageTest { | |
| private static final String APPLICATION_NAME = "Test Application"; | |
| private HttpTransport httpTransport; | |
| private Credential credential; | |
| private JsonFactory jsonFactory; | |
| private Storage storage; | |
| @BeforeClass | |
| public void setUp() throws Exception { | |
| try { | |
| httpTransport = GoogleNetHttpTransport.newTrustedTransport(); | |
| credential = CredentialsProvider.authorize(); | |
| jsonFactory = new JacksonFactory(); | |
| storage = new Storage.Builder(httpTransport, jsonFactory, credential).setApplicationName(APPLICATION_NAME).build(); | |
| } catch (GeneralSecurityException | IOException e) { | |
| e.printStackTrace(); | |
| } | |
| } | |
| @Test | |
| public void listBuckets() throws Exception { | |
| storage.buckets() | |
| .list("test-ocr-on-googl") | |
| .execute() | |
| .getItems() | |
| .forEach(i -> System.out.println(i.getName())); | |
| } | |
| } |
Listowanie zawartości bucketu
Kod jest bardzo prosty i podobny do poprzedniego:
| @Test | |
| public void listBucket() throws Exception { | |
| storage.objects() | |
| .list("blog-test") // 1 | |
| .execute() | |
| .getItems() | |
| .forEach(i -> System.out.println(i.getName())); | |
| } |
Tym razem należy podać nazwę bucketu, który chcemy wylistować [1]. Jeśli nazwa jest prawidłowa i mamy uprawnienia do tego bucketu powinniśmy dostać coś w tym rodzaju:
folder1/ //1 folder1/kot-z-serem.jpg //2 kot-z-serem.jpg
Zwróć uwagę, że folder jest listowany jako oddzielny obiekt [1], a plik w folderze listowany jest z nazwą folderu [2].
Możemy również ustawić prefix jeśli chcemy wylistować zawartość folderu:
| @Test | |
| public void listBucketWithPrefix() throws Exception { | |
| storage.objects() | |
| .list("blog-test") | |
| .setPrefix("fol") // 1 | |
| .execute() | |
| .getItems() | |
| .forEach(i -> System.out.println(i.getName())); | |
| } |
Prefix został ustawiony jako fol, i zostały wylistowane wszystkie elementy zaczynające się od tej nazwy, czyli folder1/ i folder1/kot-z-serem.jpg.
Pobieranie obiektów
Kolejną operacją jest pobranie obiektu z bucketu:
| @Test | |
| public void getObjectFromBucket() throws Exception { | |
| storage.objects() | |
| .get("blog-test", "kot-z-serem.jpg") //1 | |
| .executeMediaAndDownloadTo(new FileOutputStream("kot-z-serem.jpg")); //2 | |
| } |
Kod trochę się różni od poprzednich przykładów. Operacja jako argumenty przyjmuje nazwę bucketu i nazwę obiektu [1]. Następnie zamiast execute wywołujemy executeMediaAndDownloadTo, które jako argument przyjmuje OutputStream, do którego zapisze wynik operacji [2]. Jeśli wszystko przebiegło pomyślnie, w katalogu projektu powinien pojawić się nowy obrazek pobrany z Cloud Storage.
Wysyłanie obiektów
| @Test | |
| public void uploadObjectToBucket() throws Exception { | |
| InputStreamContent mediaContent = new InputStreamContent("image/jpeg", new FileInputStream("kot-z-serem-x.jpg")); // 1 | |
| storage.objects() | |
| .insert("blog-test", null, mediaContent) // 2 | |
| .setName("kot-z-serem-x.jpg") // 3 | |
| .execute(); | |
| listBucket(); //4 | |
| } |
Jest to chyba najbardziej skomplikowana operacja z przedstawionych, wymaga 2 linijek kodu ?. Najpierw tworzymy InputStream, z którego będziemy czytać zawartość pliku [1], biblioteka wymaga, aby podać również typ pliku. Jeśli nie znamy typu, można podać „application/octet-stream” lub po prostu null, też zadziała. Następnie podajemy nazwę bucketu [2] do którego ma zostać wysłany obiekt. Ustawiamy nazwę obiektu w buckecie [3] i wysyłamy plik poprzez execute. Ostatnią linijką jest wylistowanie zawartości bucketu [4] aby upewnić się, że plik tam trafił.
Usuwanie obiektów
Usuwanie jest bardzo proste i wymaga podania tylko nazwy bucketu oraz nazwy obiektu do usunięcia:
| @Test | |
| public void deleteObjectFromBucket() throws Exception { | |
| storage.objects() | |
| .delete("blog-test", "kot-z-serem-x2.jpg") | |
| .execute(); | |
| listBucket(); | |
| } |
Podsumowanie
Powinieneś teraz umieć wykonać proste operacje w ramach Google Cloud Storage z poziomu kodu. Operacje te są wystarczające, aby zarządzać zawartością bucketów. Cloud Storage jest podstawową usługą w ramach Google Cloud, często trzeba wysłać plik do bucketu, aby był dostępny dla innych usług. W kolejnych wpisach postaram się zademonstrować, jak można w praktyce użyć Cloud Storage, na przykład z wykorzystaniem Google Visio do rozpoznawania tekstu na obrazkach.